Highlights
- The Search team has enabled the new URL bar search experience by default 🎉 and fixed action mode layout. See bugs: 1967857, 1967721
- Check out this blog post on the new features
-

Choose how you want to search!
- As of Firefox 140, users are able to hide the Extensions button
- You can right-click on the toolbar item and choose “Remove from Toolbar”
-

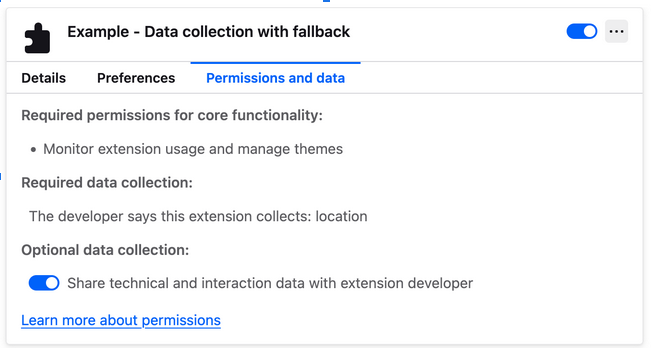
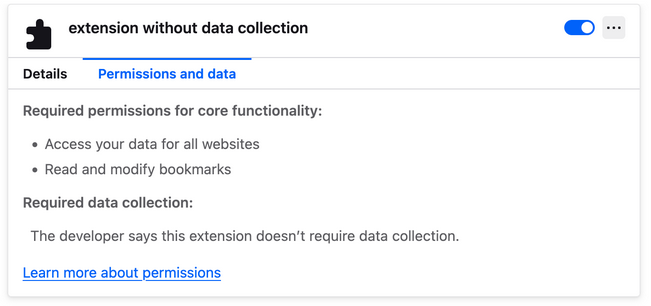
Don’t want to see the puzzle piece? Now you can remove it to reclaim some toolbar space.
-
- This was remarkably complex to get right – see these bugs for details: Bug 1948258, Bug 1948259, Bug 1948260, Bug 1948261, Bug 1948263, Bug 1966935, Bug 1964857
- You can right-click on the toolbar item and choose “Remove from Toolbar”
- Custom wallpapers / background colours for New Tab are being rolled out across all channels – see the Firefox 139 release notes here!

Friends of the Firefox team
Resolved bugs (excluding employees)
Volunteers that fixed more than one bug
- Magnus Melin [:mkmelin]
New contributors (🌟 = first patch)
- 🌟 Jilvin Jacob added various status checks to the WriteBitmap() function to handle potential write failures when saving bitmap images when setting images as the desktop background on Windows.
- 🌟 Matthias Riffard replaced hardcoded ‘transparent’ values in test_moz_button.html with CSS variables from our design system.
- 🌟 Robert Kirkman modified the nsGTKRemoteServer initialization to prevent segmentation faults when both DBus is disabled and no display server is running.
- 🌟 Rohit Borse corrected an error message displayed when attempting to take an oversized full-page screenshot with our DevTools
- 🌟 vinhle000 removed the now unused _showPreOnboardingModal function and its related test from BrowserGlue, cleaning up deprecated onboarding code.
Project Updates
Add-ons / Web Extensions
WebExtensions Framework
- As part of work to allow the WPT WebExtensions tests (initiative coordinated with other browser vendors through the WebExtensions Community Group), changes needed to load/unload extensions from the WPT marionette executor have landed in Firefox 140 – Bug 1950636
- A Nightly-only regression that prevented access to DOM storage APIs from extension iframes injected by content scripts into webpages has been fixed in Nightly 140 – Bug 1965552
WebExtension APIs
- As part of the work on the tabGroups API namespace, fixes for a few additional Chrome incompatibilities reported by extension developers have been landed in Firefox 140 and uplifted to 139 – Bug 1963825, Bug 1963830, Bug 1965007
- Support for SameSiteStatus ”unspecified” has been introduced in the Firefox WebExtensions cookies API – Bug 1550032
Addon Manager & about:addons
- More work around the Local AI models UI in about:addons has been landed in Firefox 140 (Bug 1944695, Bug 1947209, Bug 1961440, Bug 1967224)
- Fixed XPIProvider async shutdown timeout hit due to call to nsIClearData service triggered too late during an already initiated application shutdown – Bug 1967273
- Follow-ups to the NewTab built-in add-on incident hit in Firefox 138:
- New telemetry probe added in Firefox 139 to track failures to write the addonStartup.json.lz4 file back to disk (Bug 1966154), meant to help us confirm the effectiveness of the fix landed in Firefox 139 (Bug 1964281) and get better signals about other write errors that could lead to addonStartup.json.lz4 data to become stale.
- Changes applied to the XPIProvider to make sure that, in case of lost or stale addonStartup.json.lz4 data, add-ons from the app-builtin-addons (auto-installed builtins like NewTab) and app-system-addons (system-signed add-on updates got from the Application Update Service, a.k.a. Balrog) are still being detected and started early on the application startup – Bug 1964408 / Bug 1966736 (both landed in Firefox 140)
- To support serving system-signed updates to the NewTab built-in add-on outside of the release train, system-signed updates applied to built-in add-ons are no longer uninstalled when an existing Firefox profile is being upgraded to a new Firefox version – Bug 1966736 (landed in Firefox 140)
DevTools
- Rohit Borse fixed the warning message text when taking a screenshot that’s too large (#1953285)
- Keith Cirkel [:keithamus] added CloseWatcher “close” and “cancel” event listeners breakpoints (#1966702)
- Nicolas Chevobbe [:nchevobbe] added pointerrawupdate to Event Listener Breakpoints (#1957000)
- Holger Benl [:hbenl] fixed some rendering issue in the Debugger sources tree (#1967248)
- Emilio Cobos Álvarez (:emilio) fixed a regression where painting was blocked when the Debugger was paused (#1967931)
- Alexandre Poirot [:ochameau] fixed a crash that was happening when navigating to a privileged page from about:debugging when connected to Firefox for Android (#1963915)
- Nicolas Chevobbe [:nchevobbe] improved the inspector “search HTML” feature by allowing to use pseudo-element selectors (#1871881) and fixing autocomplete suggestions for pseudo elements (#1542277)
- Hubert Boma Manilla (:bomsy) fixed an issue in the Debugger where it wouldn’t scroll to expected location on pause when there was an active search (#1962417)
WebDriver BiDi
- Henrik modified the code that syncs the running state of Marionette and the Remote Agent – exposed to websites via the navigator.webdriver Web IDL attribute – between the parent and web content processes, so that it now runs asynchronously and no longer risks blocking the parent process.
- Julian fixed a bug for our browsing context events which were unexpectedly emitted for webextension Browsing Contexts – at the moment we only emit events for regular content Browsing Contexts.
- Olli Pettay improved the Actions’ implementation in both Marionette and WebDriver BiDi to prevent microtasks from being blocked while individual events are dispatched.
- Sasha added support for “acceptInsecureCerts” argument to “browser.createUserContext” command. This argument allows clients to disable or enable certificate related security settings for a specific user context (aka Firefox container) and override the settings specified for a session.
- Julian implemented a new browsing context event, browsingContext.navigationCommitted, which should be emitted as soon as a new document has been created for a navigation. Together with our other navigation events (navigationStarted, navigationFailed) this allows clients to know that a navigation is going to be completed.
- Henrik released mozdownload 1.30.0 with added support for Python 3.13.
Lint, Docs and Workflow
- Our ESLint configuration is now using the “flat” configuration.
- You may need to restart your editor after updating.
- (see above!) If you’ve worked with aboutwelcome / asrouter / newtab code, you may need to re-install the node modules for those components, e.g. ./mach npm ci –prefix browser/extensions/newtab
- Next steps are to upgrade to the latest v9 ESLint in stages to make the upgrades simpler. Bug for ESLint v9.6.0.
- Mark Kennedy enabled the lit rule no-invalid-html.
Migration Improvements
- We’ve disabled Payment Method import for Chromium-based Microsoft Edge profiles due to application-bound encryption changes. We’re currently collaborating with the Credential Management team to find creative, sustainable ways to make migrating from other browsers easier.
New Tab Page
- Lots of visual fixes for the “Sections” UI that we’ve been working on. You can manually check out Sections by setting browser.newtabpage.activity-stream.discoverystream.sections.enabled to true

Picture-in-Picture
- kpatenio fixed an issue with the cursor not hiding with other controls on fullscreen PiP windows (bug)
- kpatenio also fixed the context menu not appearing after ctrl + click over the PiP toggle on macOS (bug)
Search and Navigation
- Drew, Daisuke and Yazan fixed bugs related to suggestions favicons, sponsored label, telemetry, and enabling the Firefox Suggest, as part of its geo expansion into regions such as UK. Bugs: 1966811, 1964392, 1966328, 1966328, 1948143, 1964390, 1964979
- Mak is working on semantic history search for a future experiment. Bugs:1967985, 1968020 1967228, 1965225
- Dao fixed accessibility issue for matching tab groups when searching via ULRbar 1963884 and he’s been working on bugs related to offering tab groups in address bar 1966140, 1966337
- Mortiz is working on bugs related to on adding custom search engine dialog in about:preferences#search and is enabled by default (see 1964507 and 1967739)
-
Make search your own!

-
- Standard8 has enabled the Rust-backed engine selector for late Beta and Release 1967490
- jteow and Standard8 are working on TypeScript definitions 1966899, 1964675, 1966237, 1963781
Storybook/Reusable Components/Acorn Design System
- Graph on arewedesigntokensyet and updated how we determine token usage
- Components in development:
- new component on the way, moz-breadcrumbs
- New single-select listbox type for moz-visual-picker
- Icon support for moz-select coming soon








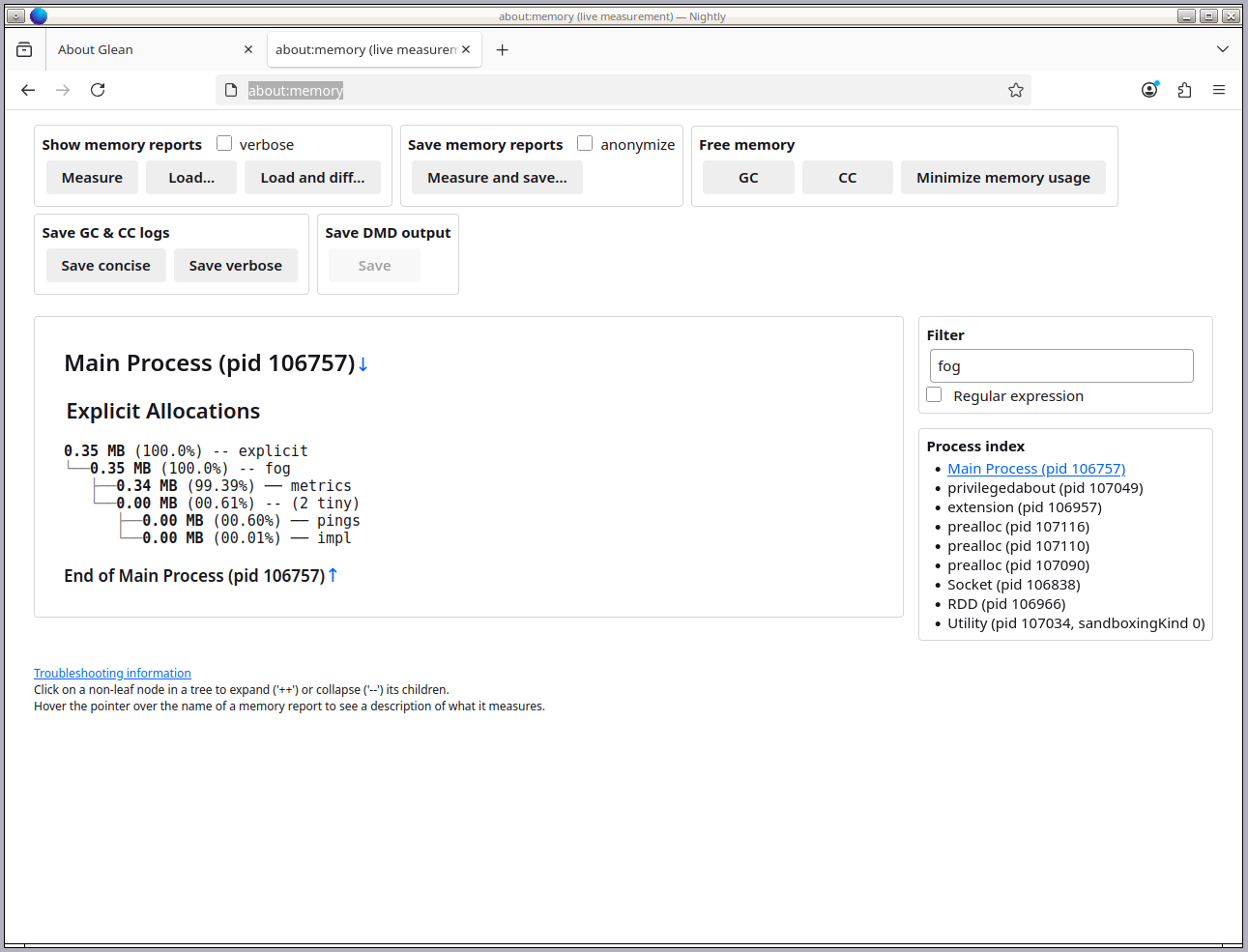
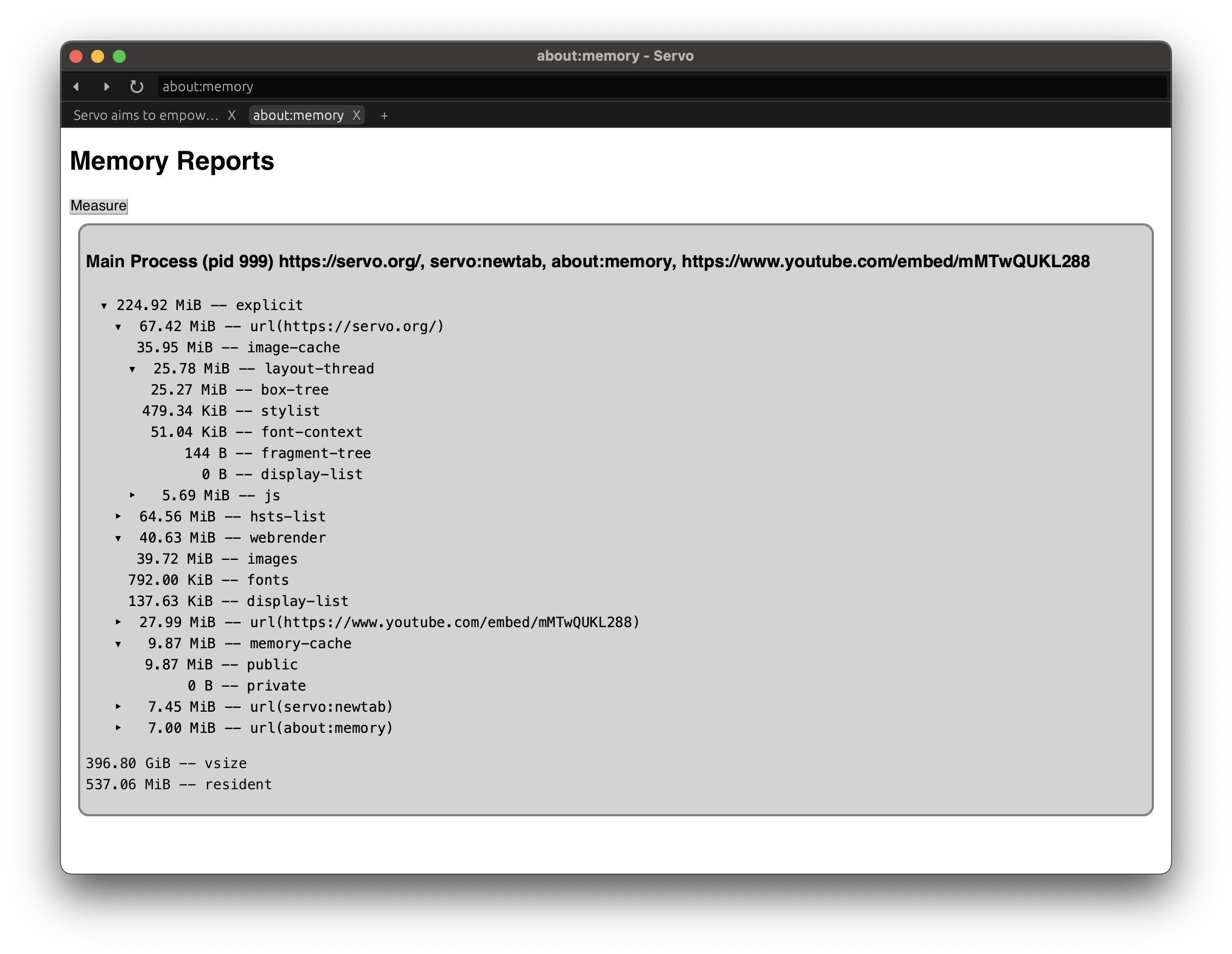
 <figcaption>about:memory on a freshly launched developer build of Firefox. fog reports 0.35 MB of allocated memory in the main process.</figcaption>
<figcaption>about:memory on a freshly launched developer build of Firefox. fog reports 0.35 MB of allocated memory in the main process.</figcaption>

 Unified search button
Unified search button 
 Easily continue your search
Easily continue your search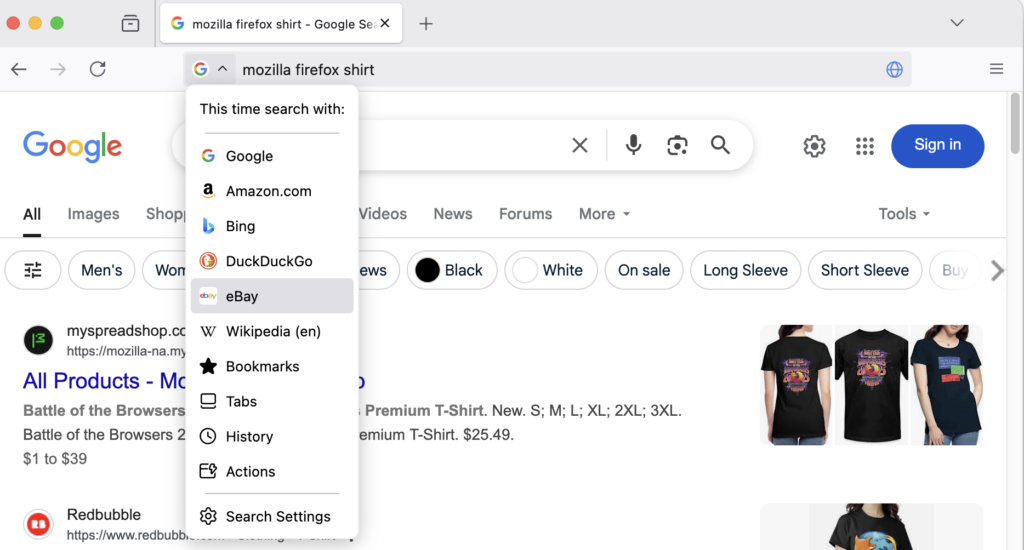
 @ Shortcuts
@ Shortcuts
 Quick Actions
Quick Actions
 Smart shortcuts
Smart shortcuts
 HTTPS trim
HTTPS trim







 Custom wallpapers for new tab
Custom wallpapers for new tab <figcaption class="wp-element-caption">Click on choose a custom wallpaper or color for New Tab</figcaption>
<figcaption class="wp-element-caption">Click on choose a custom wallpaper or color for New Tab</figcaption> <figcaption class="wp-element-caption">r</figcaption>
<figcaption class="wp-element-caption">r</figcaption>








 <figcaption class="wp-element-caption">Adlan Jackson is a writer, editor and worker-owner at Hell Gate, a New York City news publication founded as a journalist-run cooperative.</figcaption>
<figcaption class="wp-element-caption">Adlan Jackson is a writer, editor and worker-owner at Hell Gate, a New York City news publication founded as a journalist-run cooperative.</figcaption>










 <figcaption>Set AI-free Google search as the default search engine for Apple Safari, using Customized Search Engine</figcaption>
<figcaption>Set AI-free Google search as the default search engine for Apple Safari, using Customized Search Engine</figcaption>  <figcaption>This is an obvious fake “Continue” button, running as a Google ad. The same advertiser has many other ads that are misleading “Play Game” or “Download” buttons. If Google is really good at AI, why are they running so many of these?</figcaption>
<figcaption>This is an obvious fake “Continue” button, running as a Google ad. The same advertiser has many other ads that are misleading “Play Game” or “Download” buttons. If Google is really good at AI, why are they running so many of these?</figcaption>  <figcaption>5.1 billion bad ads were stopped in 2024</figcaption>
<figcaption>5.1 billion bad ads were stopped in 2024</figcaption>  <figcaption>5.5 billion bad ads were stopped in 2023</figcaption>
<figcaption>5.5 billion bad ads were stopped in 2023</figcaption>  <figcaption>1.3 billion pages taken action against in 2024</figcaption>
<figcaption>1.3 billion pages taken action against in 2024</figcaption>  <figcaption>2.1 billion pages taken action against in 2023</figcaption>
<figcaption>2.1 billion pages taken action against in 2023</figcaption> 




 ︎
︎